論文|snmalloc: A Message Passing Allocator (ISMM 2019)
「snmalloc: A Message Passing Allocator」という論文を読んだのでその紹介です。本論文は ISMM (International Symposium on Memory Management) 2019 に採択されており、論文とソースコードは GitHub (microsoft/snmalloc) で公開されています。リポジトリ名から分かる通り、著者の多くが Microsoft Research に所属しています。
免責 読み間違えている可能性があります。正確な情報が欲しい方は必ず論文を読んでください。誤りの指摘や補足、議論などは GitHub Issue や Twitter へお願いします。
更新履歴
- 2019/07/08 bump pointer と free list の next entry pointer を判定する方法について追記
- 2019/07/08 公開
概要
本論文ではマルチスレッドに対応したメモリアロケータ snmalloc の設計と実装について論じている。snmalloc はあるスレッドで割り当てられたオブジェクト1を別スレッドで解放するようなワークロード (本論文では producer / consumer 型のワークロードと呼んでいる) に最適化したメモリアロケータである。
「A Message Passing Allocator」というタイトルからメッセージパッシング (もしくはスレッド間・プロセス間通信) におけるデータシリアライゼーション用メモリアロケータに見えるが、実際は内部処理にメッセージパッシングを利用した汎用的なメモリアロケータである。スレッドをまたいだオブジェクトの解放をロックではなくメッセージキューを使って非同期に行う。
特徴
snmalloc の主な特徴は以下の通り。
- 可搬性: Windows, Linux, macOS, FreeBSD に対応。LD_PRELOAD などでシステムのメモリアロケータを置き換えて使う。
- マルチスレッドに適したヒープ構造: スレッド毎にアロケータ (per thread allocator) を持つ。オブジェクトのサイズクラス別にフリーリストを構成し、per thread アロケータが管理する2。このため基本的にメモリ割り当て時にロックがいらない。大きなサイズのオブジェクトはスレッド間で共有されるグローバルヒープによって管理する。
- メッセージパッシング: あるスレッドで割り当てたオブジェクトを別スレッドで解放する時、割り当て元スレッドのアロケータをロックせずメッセージパッシングで非同期に解放処理を行う。オブジェクトはいくつかの塊 (バッチ) で返却することで効率を上げている。受信メッセージの管理にはロックフリーキューを使い、送信メッセージの管理には基数木 (radix tree) から着想を得たキューの構成を使うことでスレッド数に対してスケールする。
- コンパクトなメタデータ: Bump Pointer-Free Lists と呼ばれるデータ構造を使うことで、 64 KiB のスラブに対して 64 bits のメタデータで済む。
解決したい問題
一般的なマルチスレッドメモリアロケータでは、スレッドをまたいだオブジェクトの割り当て・解放をする場合、元のスレッドにオブジェクトを返却せずに解放するスレッドのフリーリストにこれを追加する。これによりアロケータをロックせずにリモートオブジェクトの解放ができ、その再利用もスレッドローカルなフリーリストから取り出すだけで高速に行える。本論文ではこれを thread-caching と呼んでいる。
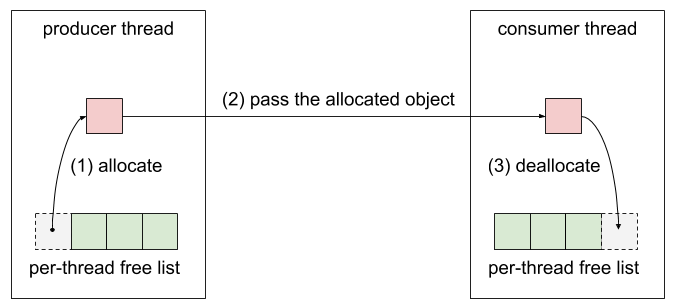
thread-caching によるリモートオブジェクトの解放処理。
thread-caching はスレッド間のオブジェクトの割り当て・解放処理が対称的に行われている時に効率的に働く。もしオブジェクトの割り当て・解放処理が特定のスレッドに偏ってしまうと、割り当て側のスレッドではフリーリストが枯渇し、解放側ではフリーリストが無駄に伸びていく。これを解消するにはスレッド間の同期処理が必要となって結局処理コストが高くなってしまう。このような非対称性は、スレッドでパイプライン処理を行うプログラムや、collector スレッドと mutator スレッドに分離しているガベージコレクタなどで起こりやすい。
snmalloc はマルチスレッドアプリケーションにおける汎用性を維持しつつ、このような非対称なワークロードに対しても効率的に働くよう設計・実装されている。
設計と実装
1. メッセージパッシング
snmalloc はクロススレッドでのオブジェクトの解放処理 (リモートオブジェクトの解放処理) をメッセージパッシングによって行う。アロケータ間の通信をメッセージキューで非同期にすることで、各スレッドアロケータは任意のタイミングでリモートオブジェクトの解放処理を進めることができる。また、リモートオブジェクトの解放処理は都度行うのではなくバッチにする。
1.1. incoming queue と outgoing queues
各スレッドアロケータは「自分宛てに届いたメッセージを溜めておくキュー (incoming queue)」と「他のスレッドに送るメッセージを溜めてバッチ化するキュー (outgoing queue)」を持つ。素朴に実装すると、outgoing queue は送り先となるスレッド数分必要になる。スレッド数はプログラム実行時に動的に変わるため、スレッド生成・終了に合わせて outgoing queue の数を増減させるか、あらかじめスレッドの最大数を決めてその数だけ outgoing queue を用意しておく必要がある。前者は実行時にオーバヘッドが生じ、かつキューの割り当てのために別のメモリ管理機構が必要になる。一方、後者は余計なメモリ空間を使うため効率が悪く、スレッド最大数が決まってしまうため汎用性に欠ける。
そこで、本提案では outgoing queues の管理を工夫することでスレッド数に関わらずスレッド毎に \(2^k\) 個のメッセージキューを持つだけで済むようにし、オーバヘッドも極力抑えるようにしている。\(k\) は設定で変更可能な値である。\(2^k\) 個はスレッド数よりも少ない可能性があるため、複数のスレッドアロケータが同じ outgoing queue に紐付けられる可能性がある。そこで本論文では outgoing queue のことを bucket とも呼ぶ。bucket のアルゴリズムについては後述する。
一方 incoming queue は複数のスレッドから remote deallocation リクエストが書き込まれる可能性がある。そこで multiple producers / single consumer に対応したロックフリーキュー3を使用する。incoming queue へのバッチメッセージの挿入は一回の atomic pointer exchange で行える。incoming queue からデータを読むときは atomic operation は必要ない。データ構造の細かい話になるのでここでは詳細を述べない。詳しくは論文内の “Remote Deallocation Queue” の項を参照。
以上を図解したのが次の図である。
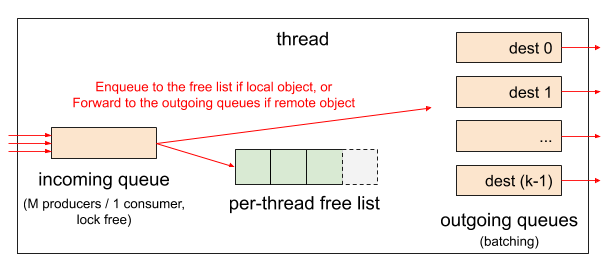
incoming queue と outgoing queues の構成。incoming queue は multiple producers / single consumer に対応したロックフリーキュー。outgoing queues は k 個ある。
スレッドアロケータは malloc もしくは free が呼ばれるたびに incoming queue をチェックし、処理を行う。バッチ内の解放予定オブジェクトを順に見ていき、管理しているアロケータ (これを owning allocator もしくは owner allocator と呼ぶ) を調べる。もしオーナーアロケータが解放処理を行っているスレッドだった場合は、メタデータを直接書き換えて現在のスレッドのフリーリストに追加する。もしオーナーアロケータが他のスレッドだった場合、オブジェクトを outgoing キューに詰め直す。
outgoing queues の各キューは linked-list で構成される。remote deallocation が起こるたびにこの linked-list にオブジェクトを追加していく。オブジェクトの持つメモリ空間を linked-list のエントリとして再利用するので、この操作に際して追加のメモリ割り当ては起こらない4。この linked-list がバッチ単位となる。linked-list が一定長に達したら送り先スレッドアロケータの incoming queue に追加する。これは atomic pointer exchange によるリストの付け替え一回で完了する。詳しくは論文内の “Remote Deallocation Queue” の項と図 3 を参照。
1.2. bucket (outgoing queue) のアルゴリズム
前述の通り、bucket (outgoing queue) は設定可能な値 \(k\) を用いて \(2^k\) 個用意する。スレッド (スレッドアロケータ) の数は \(2^k\) 個よりも多い可能性があるため、bucket とアロケータをどうマッピングしていくかが重要になる。本手法では、スレッドアロケータのアドレスを \(2^k\) で割った余り、つまりアロケータアドレスの下位 \(k\) ビットでグルーピングする。デフォルトでは \(k=6\) を使うが、以後の説明では簡略化のために \(k=2\)、つまり bucket 数が \(2^2=4\) 個の場合を見ていく。また Allocator X と表記した場合、その下位 \(k\) ビットは X であるとし、丸括弧で囲まれた数字は二進数を表すとする。
次の表はある時点の Allocator 0 と Allocator 9 の buckets を示している。Allocator 0 の buckets には Allocator 1, 2, 5, 9 に対する remote deallocation リクエストが格納されている。1 (0001), 5 (0101), 9 (1001) の下位 2 ビットはすべて (01) になるため bucket 番号 1 (01) に格納される。一方、2 (0010) の下位 2 ビットは (10) になるため bucket 番号 2 (10) に格納される。Allocator 9 の buckets には Allocator 7 に対する remote deallocation リクエストが格納されており、7 (0111) の下位 2 ビットは 3 (11) のため、bucket 番号 3 (11) に格納される。
| Bucket number | Allocator 0 | Allocator 9 |
| 0 (00) | ||
| 1 (01) | 9 (1001), 5 (0101), 1 (0001), 5 (0101) | |
| 2 (10) | 2 (0010) | |
| 3 (11) | 7 (0111) |
各 bucket の中身はバッチ化され、bucket 先頭のリクエストのターゲットアロケータに対して全て送られる。今回の例では、Allocator 0 の bucket 1 に格納されたリクエスト 9, 5, 1, 5 は全て Allocator 9 に送られ、bucket 2 に格納されたリクエスト 2 は Allocator 2 に送られる。
次の表は Allocator 9 において remote deallocation の処理を前表から 1 ラウンド進めた時の buckets を示している。Allocator 9 には Allocator 0 からバッチ (9, 5, 1, 5) が incoming queue に挿入されているが、このうちリクエスト 9 は Allocator 9 に対するリクエストなのでその場で処理され、残りのリクエスト 5, 1, 5 は下位 2 ビットの値から bucket 1 に入る。
| Bucket number | Round 1 |
| 0 (00) | |
| 1 (01) (home bucket) | 5 (0101), 1 (0001), 5 (0101) |
| 2 (10) | |
| 3 (11) | 7 (0111) |
さて、ここで home bucket という概念が登場する。初期 home bucket はアロケータアドレスの下位 \(k=2\) ビットの bucket になる。つまり Allocator 9 (1001) では bucket 1 (01) となる。
home bucket は 1 ラウンド進むたびに違う bucket へと変更される。この新しい bucket は下位 \(k\) ビットの隣の \(k\) ビットが使われる。Allocator 9 (1001) の場合は bucket 2 (10) に変更される。この home bucket が変更されるタイミングで、元の home bucket に入っていたリクエストは outgoing queues 内で再配分される。
これを考慮してさらに 1 ラウンド進めた時の buckets の様子が次の表である。リクエスト 1, 5 はそれぞれ (0001), (0101) なので、次の \(k=2\) ビットを取り出すとそれぞれ (00), (01) となる。よってリクエスト 1 は bucket 0 へ、リクエスト 5 は bucket 1 へ再配分される。前ラウンドで bucket 3 に入っていたリクエスト 7 は Allocator 7 へ転送される。
| Bucket number | Round 2 |
| 0 (00) | 1 (0001), |
| 1 (01) | 5 (0101), 5 (0101) |
| 2 (10) (home bucket) | |
| 3 (11) |
次の round 3 ではリクエスト 1 は Allocator 1 へ、リクエスト 5 は Allocator 5 へ転送されるので、Allocator 9 の buckets は空になり、remote deallocation が終了する。
以上が buckets による remote deallocation リクエストの転送アルゴリズムである。このように、remote deallocation リクエストが目的のアロケータに到着するまでには複数回のアロケータホップが発生する可能性がある。
識別子として使うビット数を \(N\) とすると、転送回数は高々 \(\lceil N/k \rceil\) 回となる。64 ビットアーキテクチャで実際にアドレスとして使われるのが 48 ビットとし、アロケータを 2 KiB (\(2^{11}\) bytes) アラインメントにすると下位 11 ビットは無視できるため、実際に識別子として使うのは 37 ビットになる。\(k=6\) とすると、最悪でも \(\lceil 37/6 \rceil = 7\) 回のホップで十分であることが分かる。論文では、ホップ数がかさむケースは稀であり、大抵の場合は直接目的のアロケータまで送ることができると述べられている。
2. メモリの管理
本手法では、仮想アドレス空間を chunk という単位に分割して扱う。chunk サイズは自由に設定可能だが、論文中では \(2^{24}\) bytes (16 MiB) を使う。chunk を使ってオブジェクト割り当ての管理を行うグローバルヒープ (large objects) とスレッドローカルスラブ (medium slabs, superslabs) を構成する。スレッドローカルスラブを二つのサイズクラスに分けているのが特徴である。
- Large Objects : 1 chunk 以上 (16 MiB 以上) のオブジェクトをスレッドグローバルに管理する。複数のサイズクラスを構成する。
- Medium Slabs : 64 KiB 以上 16 MiB 未満のオブジェクトをスレッド毎に管理する。スラブ全体が 1 chunk で構成される。
- Superslabs : 64 KiB 未満のオブジェクトをスレッド毎に管理する。スラブ全体が 1 chunk で構成される。superslab は更に複数の small slabs に分割され、それぞれが Bump Pointer-Free Lists (後述) によって管理される。
2.1. Global Pagemap
Global Pagemap は chunk の管理を行うコンポーネントである。スレッドグローバルに存在する。chunk 毎に 1 byte 割り当て、下記の情報を管理する。
- Unknown : snmalloc で未管理の領域。
- Super : superslab の chunk。
- Medium : medium slab の chunk。
- Large(n) : \(2^n\) chunk で構成される large object のスタート chunk。
- Jump(m) : large object の中間 chunk。少なくとも \(2^m\) chunks 前にスタート chunk がある。Jump はアロケータの実装には必要ないがデバッグに有用。
chunk のサイズは \(2^{24}\) bytes (16 MiB) であるため、48 ビットのアドレス空間には最大で
\[\frac{AddressSpace}{ChunkSize} = \frac{2^{48} bytes}{2^{24} bytes} = 2^{24}\]\(2^{24}\) 個の chunk がある。1 chunk 辺り 1 byte の情報なので、最大で \(2^{24}\) bytes (16 MiB) のマップで管理できます。
2.2. Large Objects
Large objects は 2 の累乗単位 (\(16 \times 2^0\), \(16 \times 2^1\), \(16 \times 2^2\), …) のサイズクラスで構成され、サイズクラス毎にロックフリーなスタック (Treiber stack5) を使ってスレッドグローバルに管理する。
2.3. Medium Slabs
Medium Slabs は 64 KiB 以上 16 MiB 未満のオブジェクトをスレッド毎に管理する。各スラブは 1 chunk で構成される。次の図は Medium Slabs のメモリレイアウトを示している。
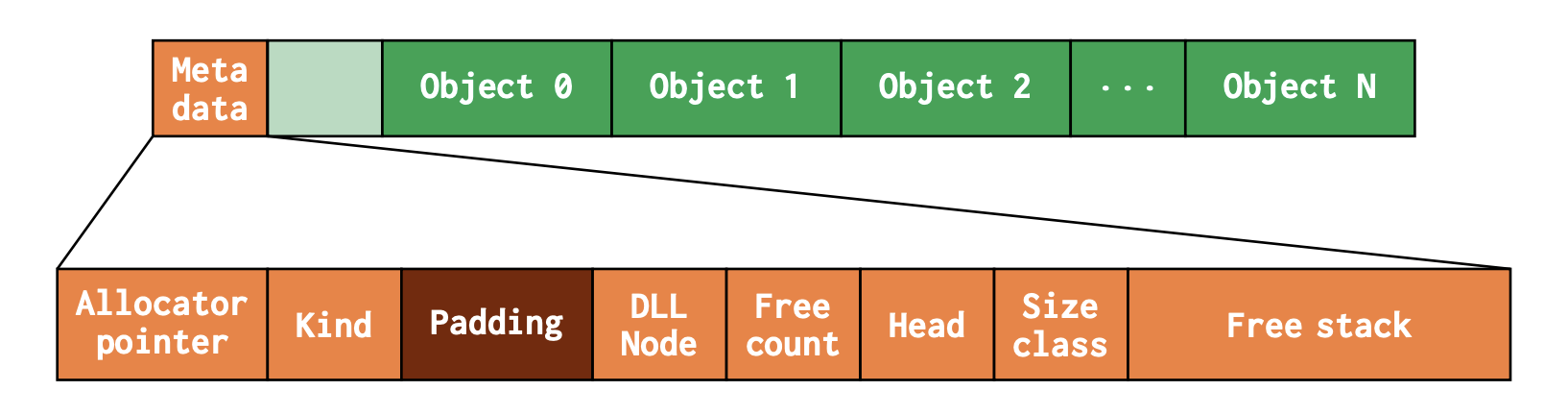
Medium Slab のメモリレイアウト。論文より引用。
スラブの先頭はメタデータになっており、メタデータの先頭にはオーナーアロケータへのポインタとスラブの種類 (kind: medium or super) が格納されている。オーナーアロケータへのポインタは remote deallocation で必要になる。kind は chunk 単位で pagemap も管理しているが、スラブにも持たせることでグローバルな pagemap へのアクセスを不要にしている。これらの情報はスラブ構築時に一度だけ書き込まれ、あとは複数のスレッドから排他制御せずにアクセスされる。頻繁にアクセスされるため、キャッシュラインのギリギリまで padding して全体を read-only にすることでキャッシュラインの無効化を防いでいる。
DLL Node (128 bits) は Doubly Linked List のこと。同一のスレッド・同一のスラブ種類で未使用オブジェクトを持つ Medium Slabs を繋いだリストである。使用可能な Medium Slab を探す時に使う。Free Count (16 bits) はスラブ内のフリーオブジェクトの数。Free Stack (512 bytes) はスラブ内の未使用オブジェクトを管理する linked list。Head (8 bits) は Free Stack の先頭オブジェクトのインデックス。Head に絶対アドレスのポインタではなく相対的なインデックスを用いることでメタデータを小さくしている (関連研究の項を参照)。Size-Class (8 bits) はこのスラブ内のオブジェクトのサイズクラスを示す。
スラブ内に 2 つの linked list があって分かりにくいが、doubly linked list は空き領域を持つ medium slabs 間を繋ぐもので、free stack は medium slab 内の未使用オブジェクトを繋ぐ linked list である。
2.4. Superslabs
Superslabs は 64 KiB 未満のオブジェクトをスレッド毎に管理する。各 Superslab は 1 chunk で構成される。次の図は Superslab のメモリレイアウトを示している。
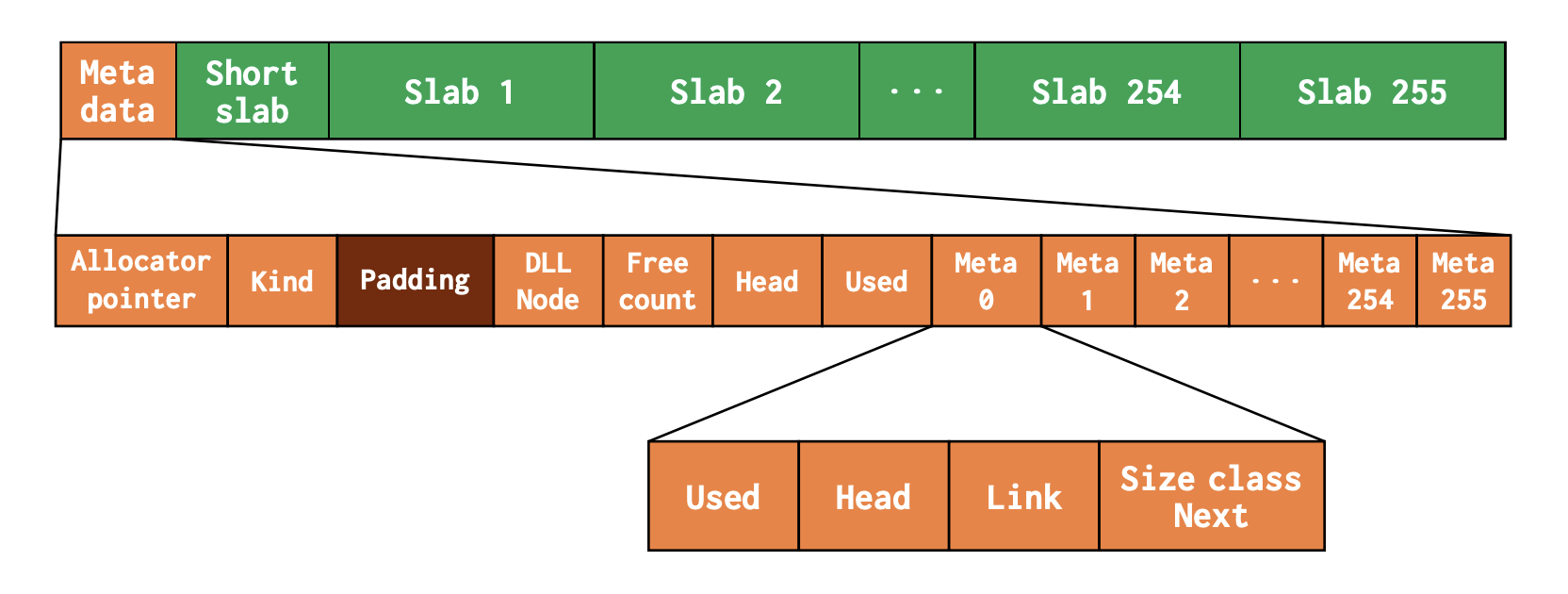
Superslab のメモリレイアウト。論文より引用。
Superslab は更に Small Slabs を持つ入れ子構造になっている。Small Slab は 64 KiB で、各 Superslab に 256 個格納されている (図中の Slab 1-255)。Superslab の最初の 64 KiB は特殊で、Superslab 全体を管理するメタデータと Short Slab で構成される。Short Slab はメタデータの分 2 KiB 小さいことを除けば、他の Small Slab とほぼ同じである。
メタデータは Free Count までは Medium Slabs と同じ。Head はメタデータ内に格納された割り当て可能な Small Slab のインデックスを指す。Used は使用済みの Small Slabs の数。このカウント方法が少し変わっていて、通常の Small Slabs は 2 としてカウントし、Short Slab は 1 としてカウントする。Superslab が完全に割り当てられると \(255 \times 2 + 1 = 511\) となる。恐らく Used の偶奇性で Small Slab が使用済みかどうか簡単に判別できるようにしている。
Used の後には Small Slab 毎のメタデータが格納されている (図中の Meta 0-255)。Small Slabs のメタデータは Used / Head / Link / Size Class Next というフィールドによって構成されている。Used はその Small Slab が使用済みかどうかを示し、Size Class Next が次の未使用 Small Slab を指す。Head, Link は次節で述べる。
2.5. Bump Pointer-Free Lists
Small Slabs 内の未使用領域は Bump Pointer-Free Lists と呼ばれる仕組みによって管理される。仰々しい名前だが、これは単に Bump Pointer と Free Lists という 2 つのメモリ割り当て手法を組み合わせたものである。Free Lists はその名の通り利用可能なオブジェクトを linked list で管理するごく一般的な手法である。Bump Pointer も単純な仕組みであるが、単純ゆえに逆にあまり知られていない気もするのでここで軽く説明する6。
Bump Pointer Allocation: あるメモリ領域を順番に割り当てていくことを考える。領域の範囲は「領域の先頭を指すポインタ」と「領域の最後を指すポインタ」の二つがあれば表現できる。この領域を素朴に順番に割り当てていくには、要求されたサイズ分だけ先頭ポインタをずらし、ずらす前の先頭ポインタを呼び出し元に返せば良い。このポインタをずらす操作を bump と呼び、空き領域の先頭を指すポインタを bump pointer という。この手法によるメモリ割り当てが Bump Pointer Allocation7 である。なお、領域の最後を指すポインタは limit pointer という。bump pointer allocation は実装が簡単で効率も良い反面、オブジェクトの解放処理を簡単にできないという欠点がある。メモリを割り当てっぱなしにする場合や、まとめて解放するような場合には向くが、汎用的ではない。
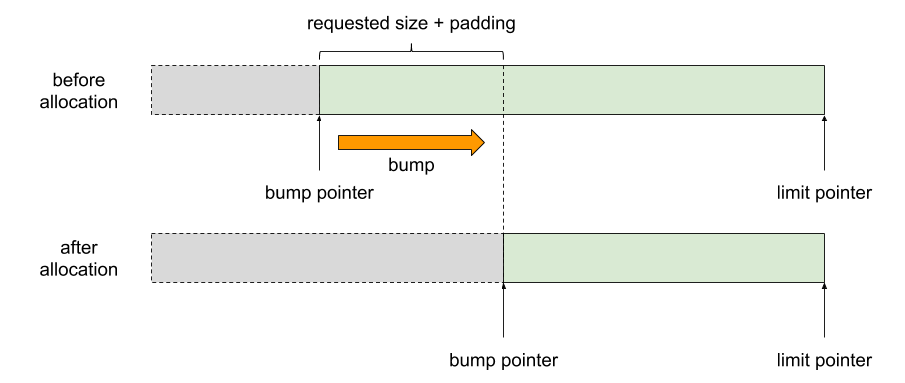
bump pointer allocation によるメモリ割り当て。グレーが割り当て済み領域、緑が未使用領域。要求されたサイズ分 bump pointer をずらし、元の bump pointer を返す。
さて話を Bump Pointer-Free Lists に戻す。前述の通り、これは Bump Pointer と Free Lists を組み合わせた手法である。
まず未使用の Small Slab からメモリを割り当てる場合を見ていく。このスラブの持つ領域を Bump Pointer Allocation で割り当てていき、Head に bump pointer を格納する。オブジェクトの割り当てが進むと、領域の前半部分が使用済みとなり、後半部分が空き領域となる。
次に割り当てられたオブジェクトを解放するときを考える。まず解放したオブジェクトを使って free list を構築する。free list の最後のエントリの指すポインタを bump pointer にし、Head が free list の先頭エントリを指すようにする。これにより、free list と bump pointer がシームレスに接続される。この手法により、free list と bump pointer がすべてスラブ内で管理され、それらを別途メタデータとして管理する場合に比べてメモリの使用効率が向上する。
2019/07/08 追記: スラブからメモリを割り当てるとき、今見ているポインタが bump pointer なのか free list の next entry pointer なのかを判定する必要がある。これはポインタの下位ビット (タグ) でできる。ビットが立っていれば bump pointer である。ポインタが -1 の場合は free list の終わりで、かつ bump 領域が空であることを示す。
次の図は、free list と bump poiner が混在した状況を示している。Head から伸びた赤矢印が free list の先頭エントリを指し、そこから伸びた緑矢印が free list の二つ目のエントリを指す。二つ目のエントリから伸びた緑矢印は bump pointer で、後半の未使用 bump 領域の先頭を指している。bump 領域の最後のエントリは doubly linked list のエントリとなっており、空き領域を持つ Small Slabs を繋げている。Link はこの doubly linked list エントリへのポインタを保持する。新たにオブジェクトを割り当てる場合は、Head が指す free list の最初のエントリが使われる。
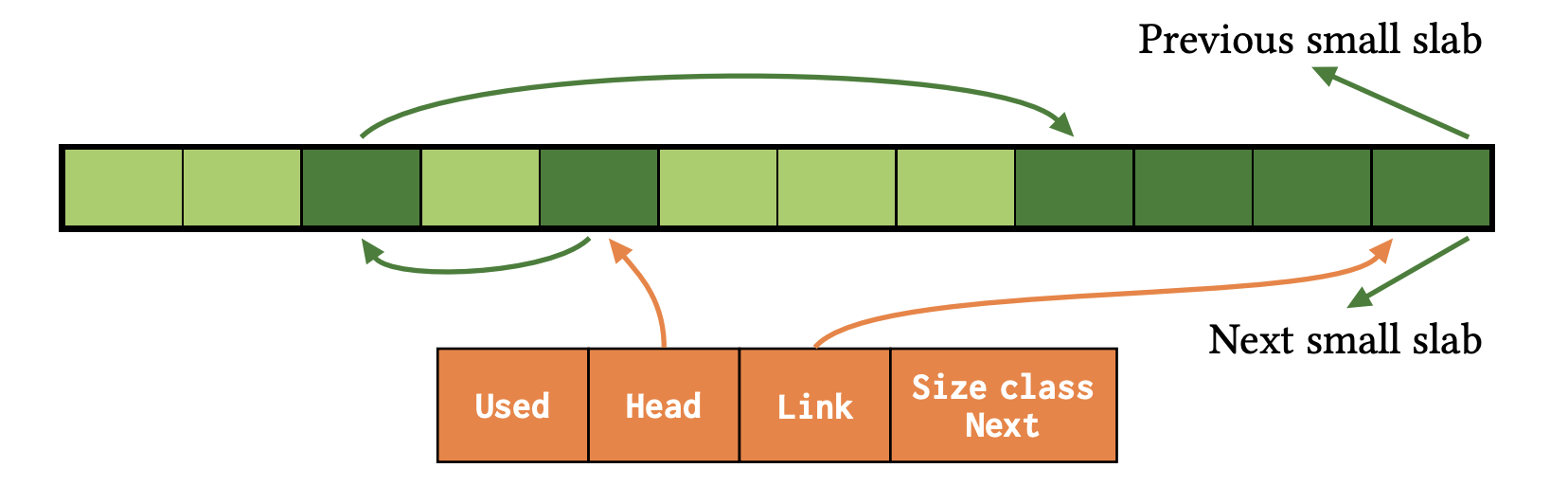
bump pointer-free lists において両者が混在している状態。論文より引用。
次の図は、bump 領域を使い切った状態を示している。Head から順に 3 つの free list エントリへポインタが連結している。最後のエントリは doubly linked list のエントリなっており、Link がそれへのポインタを保持している。
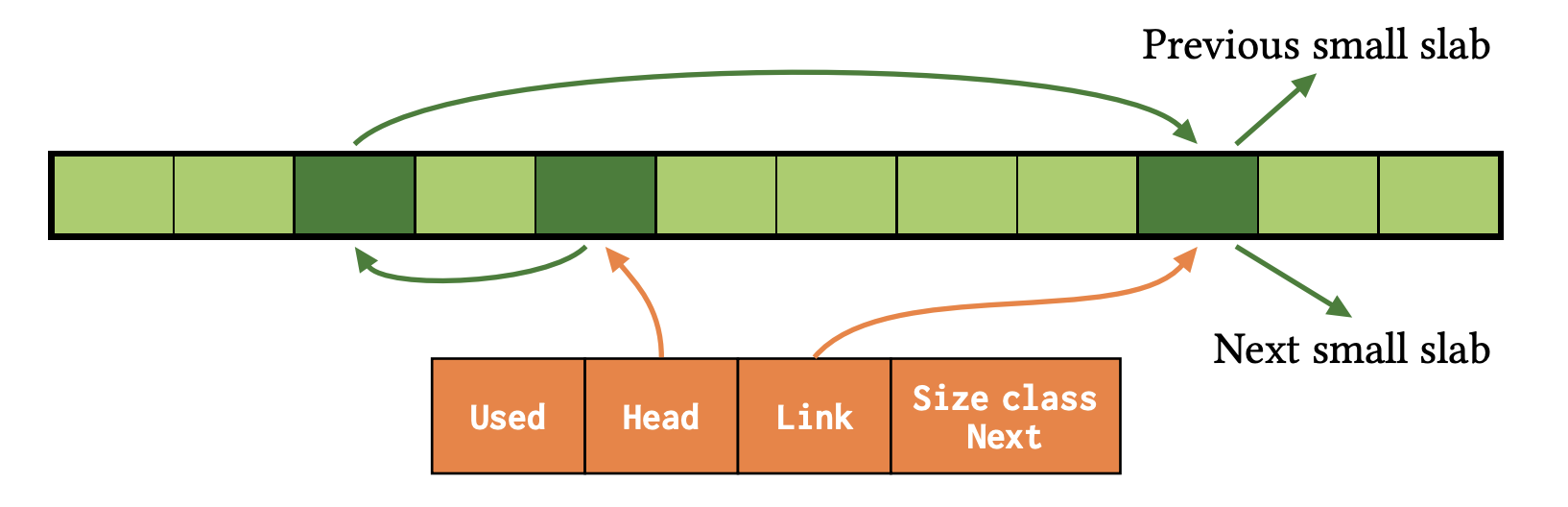
bump pointer-free lists において bump 領域を使い切った状態。論文より引用。
Bump Pointer-Free Lists によって、メタデータとして bump pointer や doubly linked list のポインタを格納するよりメモリ使用量を抑えることができる。
3. ポータビリティ
本論文では OS 間でのポータビリティを維持するために注意した点 (e.g., physical pages の lazy commit やメモリのアラインメント) などが記載されているが、割と細かい話なので割愛する。興味のある方は論文を読んでください。
評価
評価はマイクロベンチマークとリアルアプリケーションを使って行った。比較対象として Hoard, jemalloc, lockfree, lockless, ptmalloc, rpmalloc, scalloc, SuperMalloc, tbbmaloc, tcmalloc で測定8。
マイクロベンチマーク
マイクロベンチマークは二種類。ベンチマーク実行マシンは Ubuntu 18.04 Standard F64s_v2 (64 vcpus, 128 GB memory) Azure virtual machine。
Symmetric Workload: 「割り当てたオブジェクトを別スレッドに渡し、受け取り側のスレッドで解放」という操作をスレッド間で対称的に行うワークロード。普段はクロススレッドで解法処理を行わないアロケータ (他スレッドから渡されたオブジェクトを自スレッドのフリーリストに追加するようなアロケータ、thread-caching アロケータ) はスレッド間で排他制御する必要がなく、解放したオブジェクトを同期処理なしで再利用できるため有利になる。
結果が次のグラフ。jemalloc, tcmalloc, SuperMalloc が良い性能を示していることが分かる。snmalloc は多くのアロケータよりも安定して良い性能を示しているが、軽量とはいえ常にメッセージパッシングによって解放済みオブジェクトを割り当て元スレッドに返却するため、jemalloc, tcmalloc, SuperMalloc 程は性能が出ていない。
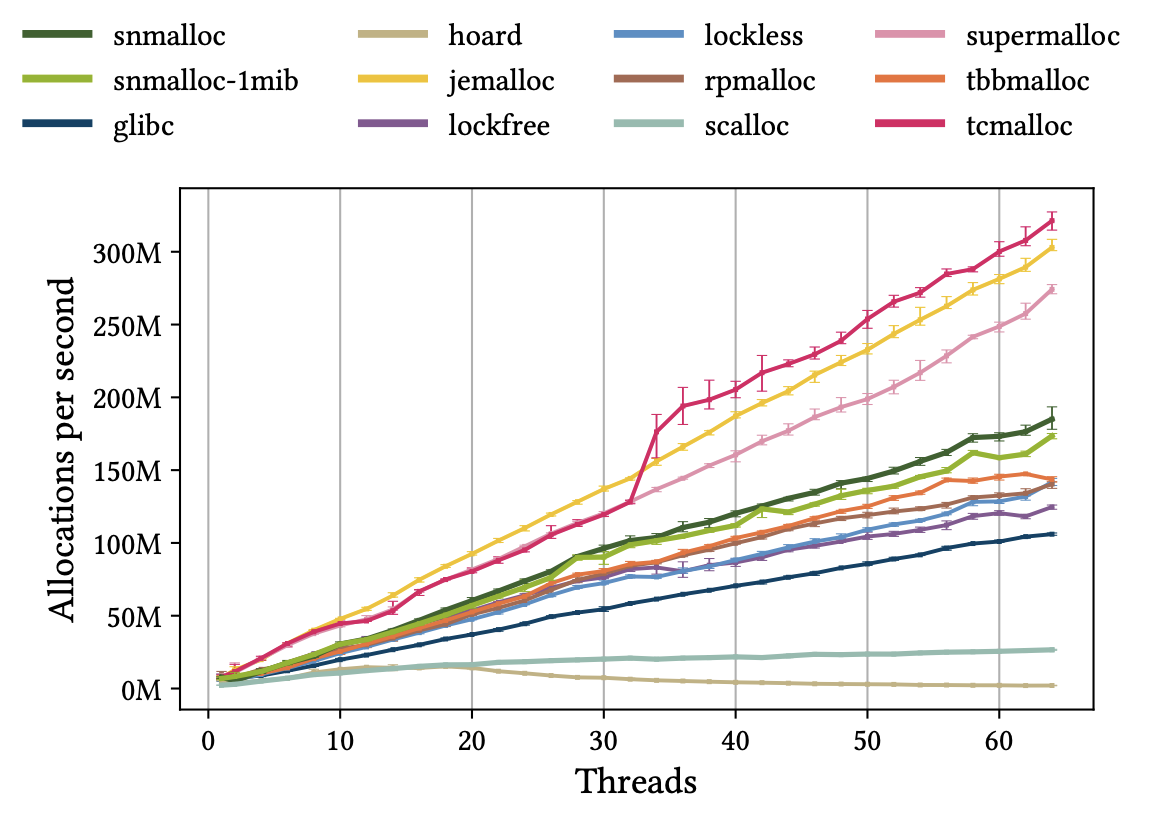
symmetric workload の実行結果。スレッド数を増やした時の秒間割り当て数の変化を示している。論文より引用。
Producer/Consumer (Asymmetric Workload): 「あるスレッド (Producer Thread) はひたすらオブジェクトを割り当てて別スレッドに渡し、受け取り側のスレッド (Consumer Thread) はひたすら解放する」という操作を行うワークロード。SuperMalloc の持つベンチマークを使っている。producer thread と consumer thread は半分ずつ。
結果が次のグラフ。thread-caching アロケータの性能が悪いことが分かる。特に tcmalloc は全くスケールしていない。thread-caching アロケータでは consumer thread のスレッドヒープが肥大化し、一方で producer thread のスレッドヒープが枯渇するため、オブジェクト割り当てのためにグローバルヒープへのメモリ追加要求が必要になる。これは同期処理や複雑なヒープ構造によって高コストであるため性能が伸び悩む。一方、snmalloc はスレッド数が増えてもスケールし、最も良い性能を示している。これはメッセージパッシングを使ったバッチでのクロススレッド解放処理により、同期コストが抑えられているためである。
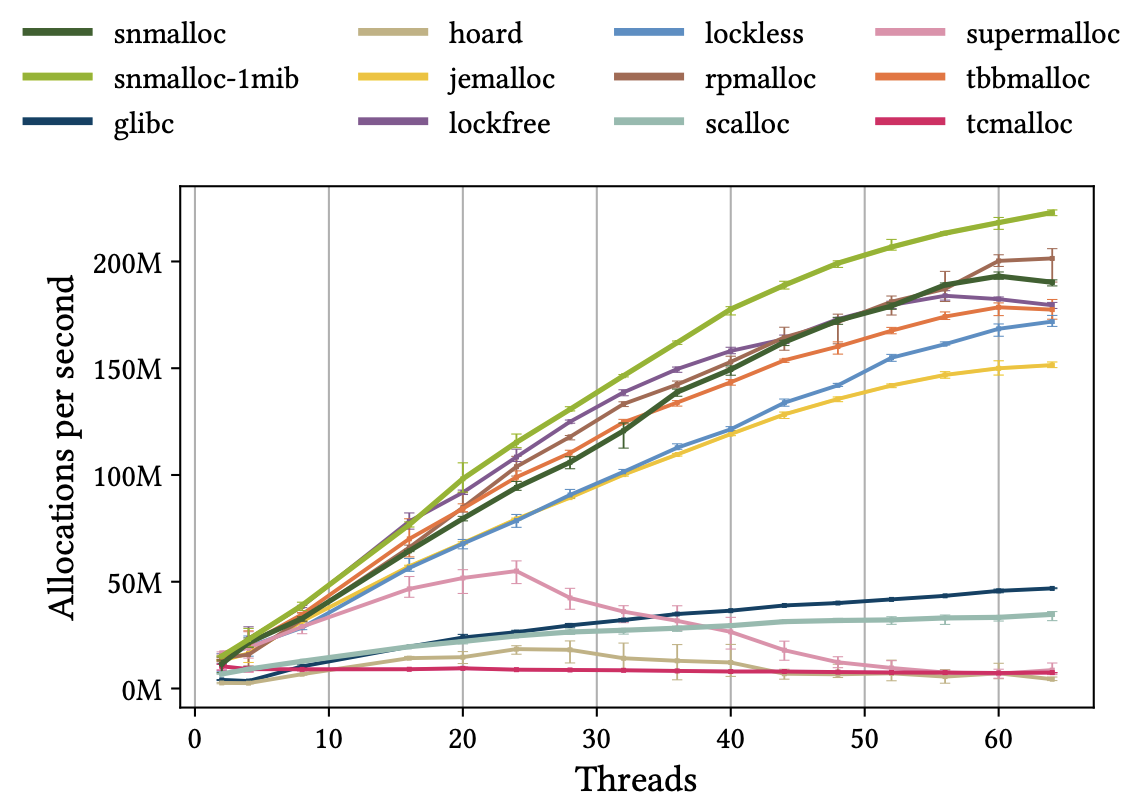
producer/consumer (asymmetric workload) の実行結果。スレッド数を増やした時の秒間割り当て数の変化を示している。論文より引用。
論文中では空間オーバヘッドやウォームアップタイムについての性能評価も行われているがここでは割愛する。詳しくは論文を読んでください。
リアルアプリケーションベンチマーク
リアルアプリケーションによるベンチマークは二種類。
FaRM: FaRM は Microsoft が開発している分散オンメモリ計算環境で、Bing サーチエンジンの中で使われている。これを使って性能測定を行っている。ベンチマークには Yahoo! Cloud Serving Benchmark を FaRM 向けにして使用。これに三種類のメモリアロケータ (snmalloc, Rockall, memory pooling) を組み込んで実行。Rockall は FaRM にビルトインされたサイズクラスベースなアロケータ。Memory pooling はクリティカルパス上で使うメモリをあらかじめプールしておくアロケータ。Pooling によってメモリ割り当てのコストをなくせるため理想的だが多大なチューニングが必要になるため汎用的ではない。
結果が次のグラフ。デフォルトの Rockall に比べて 3.5-22% の性能向上で、このワークロード向けにチューニングされた memory pooling に比べても 1-2.5% しか変わらない。
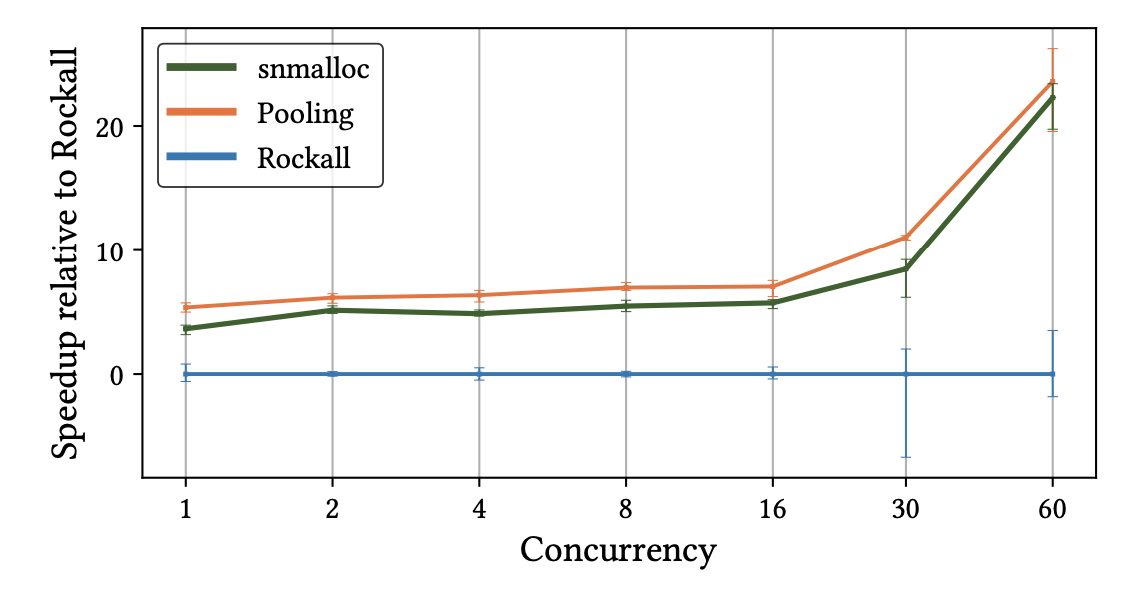
FaRM によるリアルアプリケーションベンチマークの実行結果。デフォルトのアロケータである Rockall をベースラインに、並列数を上げた時の実行速度の変化を示している。論文より引用。
SPECspeed Integer: SPECspeed Integer はベンチマークコレクション。このベンチマークの大部分はシングルスレッドで動くため、snmalloc のメッセージパッシングデザインは有利にはならない。これをマイクロベンチマークで使用したものと同じアロケータたちと比較。詳細は省くが他のアロケータと比べて良い性能を示しており、汎用的なアロケータとしても優れていることが分かる。論文にはグラフやより詳細な解説が載っているのでそちらを参照。
関連研究
snmalloc の特徴は効率的なメッセージパッシングによるリモートオブジェクトの解放と、コンパクトなスラブメタデータにある。
- Slabs of Uniformly Sized Objects: 既存のメモリアロケータ (Hoard, SuperMalloc, rpmalloc, tbbmaloc) は一種類のスラブサイズを使用しているのに対し、snmalloc は medium と small という二種類のスラブサイズを使用している。
- Owned Heaps: rpmalloc, tbbmalloc, lockless, scalloc は snmalloc と同じようにスレッド毎にアロケータを持っており、remote deallocation に対応するためにオブジェクトを割り当て元のスレッドアロケータに返却する。しかしこれらはバッチでの解放処理には対応していない。tbbmalloc, lockless, scalloc はスラブ毎にキューを持つことで負荷分散しているが代わりにメタデータのサイズが大きくなっている。
- Shared Heaps: SuperMalloc, tcmalloc は一つのグローバルヒープを使っているのに対し、Hoard, jemalloc, ptmalloc は複数のヒープを使っている。複数のヒープを使うことで同期処理を減らせるが、remote deallocation では依然として同期処理が必要になるため、thread-caching でこれを改善している。SuperMalloc はさらにグローバルなキャッシュと CPU 毎のキャッシュを用いてコンテンションを減らす工夫をしている。
- Free Space Tracking: snmalloc と同様に、多くのアロケータが bump pointer allocation と free lists を併用して未使用オブジェクトを管理している。しかし、SuperMalloc, rpmalloc, tbbmalloc, scalloc, Hoard は bump pointer と free list のポインタを別に管理しているためメモリ効率が落ちている。lockless は free list の最後に bump pointer を格納する同様のアプローチを取っているが、メタデータに絶対アドレスのポインタを格納しているため snmalloc よりもメタデータが大きい。
まとめと雑感
snmalloc は既存のメモリアロケータの特徴を活かしつつ、従来苦手だった非対称型のワークロードにも適合するよう上手に進化させたメモリアロケータでした。さらに Bump Pointer-Free Lists などの手法を使うことでメタデータをコンパクトにしてメモリの使用効率を高めています。汎用性も高く、色々なユースケースで利用できそうです。
笹田さん9に教えてもらったのですが、元々は Pony というプログラミング言語用のメモリアロケータだったそうです。確かに論文中に Pony について言及3がありますし、そもそも論文著者の一人は Pony で博士論文10を書いている人でした。Pony の特徴であるアクターモデルにもピッタリ合いそうです。
ああー、なるほど!論文中に「クロススレッドの deallocation は Pony lang の message queue をベースにした lock-free queue を使う」って部分があるんですが、そういう背景だったんですね。そこから参照されてる論文[3]の著者を見たら、この論文の著者の一人でした :)
— nhiroki (@nhiroki_) 2019年6月26日
ところで Microsoft は ISMM 2019 の発表の裏で mimalloc という別の汎用メモリアロケータを公開しました。比較対象に snmalloc も挙げられていてとても気になっています。mimalloc のテクニカルレポートを見ると謝辞に snmalloc の著者が挙げられているので、どうやら両チームは協力して開発しているようです。設計思想もだいぶ違うようなので、次はこのテクニカルレポートを読んでみようと思っています。
注釈
-
本論文では一回の allocation, deallocation で扱う連続したメモリ領域を「オブジェクト」と呼んでいる / “We use the term object to describe a consecutive piece of memory that has been allocated as the result of a single allocation, which in turn must be freed as a single unit.” ↩
-
論文中では “size-specific thread-local lists” と書かれている。マルチスレッドを意識したモダンなメモリアロケータ (tcmalloc など) はみんなこの構成。 ↩
-
“The queue for remote deallocations is a lock-free queue based on the Pony language runtime [3, 4] message queue. It allows multiple producers and a single consumer.” ↩ ↩2
-
各エントリは「次のエントリへのポインタ」と「オブジェクトの属するアロケータへのポインタ」を持つ必要があるため、オブジェクトの最小サイズはポインタサイズの二倍になる。 ↩
-
“The Treiber stack algorithm is a scalable lock-free stack utilizing the fine-grained concurrency primitive compare-and-swap. It is believed that R. Kent Treiber was the first to publish it in his 1986 article “Systems Programming: Coping with Parallelism”.” / Treiber stack - Wikipedia ↩
-
Bump Pointer Allocation について日本語で最もまとまっているのは『ガベージコレクション ― 自動的メモリ管理を構成する理論と実装』だと思います。むしろそれしか見つけられませんでした。本記事もこの本の「7.1 逐次割り付け」を参考にしました。 ↩
-
Sequential Allocation とも呼ばれる。 ↩
-
jemalloc は FreeBSD や Firefox、ptmalloc は glibc、tbbmalloc は Intel TBB、tcmalloc は gperftools などで使われている。Hoard は昔サーベイしたはずなんですがすっかり忘れている。他のは知らないので気が向いたら論文など読みたい。 ↩
-
ISMM 2019 の現地で発表を聞かれたそうです。ちなみに笹田さんは同学会で「Gradual Write-Barrier Insertion into a Ruby Interpreter」という論文を発表されています。 ↩
-
Sylvan Clebsch. 2018. Pony: co-designing a type system and a runtime. PhD thesis, Imperial College London. ↩