リソースの読み込みを助けるウェブブラウザ API の世界
ウェブブラウザはネットワークから様々なリソースを集め、それらを処理して組み合わせてウェブページをレンダリングします。リソースが揃わないとレンダリングできないので、この一連の処理のどこかが遅れるとページの表示も遅くなります。レンダリングをすみやかに開始できるようにウェブブラウザはリソースの取得やその処理を最適化するための API を提供しています。本記事ではそれらを網羅的に紹介し、ウェブアプリの性能改善を図る上でどのようなブラウザ機能が使えるのかを知ってもらうことを目的としています。各機能の具体的な適用事例については他の記事に委ねます。
本記事の内容は記事公開時点での情報に基づいており、閲覧時点では既に古くなっている可能性があります。最新の正確な情報は一次情報源を参照してください。また特定のブラウザ実装について言及する場合は、断りがない限り Chrome を想定しています。誤りや補足、質問などは GitHub Issue もしくは Twitter へお寄せください。
目次
- 概要
- 用語
- アプローチ
- メトリクス
- リソースの先読みに関する API
- dns-prefetch
- preconnect
- prefetch
- preload
- modulepreload
- prerender
- リソースの優先度制御に関する API
- Priority Hints
- Lazy Loading
- スクリプトの async と defer
- その他の API
- HTTP/2 Server Push
- 103 Early Hints
- Service Worker と Cache Storage
- Web Bundle
- まとめ
- 参考文献
概要
用語
説明を簡単にするために用語を整理します。
- ナビゲーション:a タグのクリックなどによってページが遷移することです。
- リソース:ウェブページを構成するファイルです。リソースにはメインリソースとサブリソースがあります。メインリソースはページ表示の起点となるファイル、つまり HTML ファイルのことです1。サブリソースはメインリソース以外のリソース全てです。代表的なものはスクリプトファイル、スタイルシート、画像、ウェブフォントなどです。
- フェッチ:ネットワークを介してリソースを取得することです。
- ロード:フェッチしてきたリソースをデコードしてメモリ上に展開して使える状態にすることです。例えば HTML のパースやメモリキャッシュへの画像読み込みが行われます。
アプローチ
レンダリングをすみやかに開始するにはリソースフェッチやロードを素早く終わらせる必要があります。これにはいくつかのアプローチが考えられます。
- フェッチやロード自体の処理時間を短くする。素朴な方法はユーザに高速なネットワークやパワフルなデバイスを使ってもらうことですが、それらをユーザに求めるのはなかなか難しいでしょう。今あるネットワークやデバイスを最大限活用するために、HTTP/2 や HTTP/3 といった新しくより効率的なネットワークプロトコルを採用したり、処理をマルチスレッド化したり、リソース自体を最適化 (分割・圧縮・バンドル) したりすることが現実的な策になりそうです。
- 重要なリソースを先読みする。既知の重要度の高いリソース (例えばメインリソース) などはブラウザがある程度自動で先読みをすることがありますが、何が重要なリソースかはアプリケーションによって違うため、アプリケーションからブラウザに対して先読みヒントを与える API が用意されています。また先読みした後どこまで処理を進めるかによって、さらにいくつかの種類に分類されます。
- 重要じゃないリソースを後回しにする。あらゆるリソースを先読みしようとすると、ネットワークや計算資源を使い切ってしまい、逆にレンダリングが遅くなることがあります。重要じゃないリソースの処理を後回しにすることで、相対的に重要なリソースの処理を優先することができます。
(1) のアプローチのうち、マルチスレッド化については以前記事を書きました。
本記事では主に (2) と (3) のアプローチについて紹介します。
メトリクス
性能を改善するには性能を定量的に表現することが重要です。ウェブアプリケーションの性能を定量化した指標 (メトリクス) は数多くありますが、特に最近注目を集めているのが Google が提唱している Core Web Vitals です。これは LCP (Largest Contentful Paint), FID (First Input Delay), CLS (Cumulative Layout Shift) と呼ばれる 3 つのメトリクスで構成されています。以下は Google Developers ブログからの引用です。
- Largest Contentful Paint は、ユーザーがページで最も有意義なコンテンツをどのくらい早く見ることができるかを表します。感覚的な読み込みスピードを測定し、ページ読み込みタイムラインにおいてページの主要コンテンツが読み込まれたと思われるタイミングを指します。
- First Input Delay は、最初の入力までの遅延を表します。応答性を測定して、ユーザーが最初にページを操作しようとする場合に感じるエクスペリエンスを定量化します。
- Cumulative Layout Shift は、ページがどのくらい安定しているように感じられるかを表します。視覚的な安定性を測定し、表示されるページ コンテンツにおける予期しないレイアウトのずれの量を定量化します。
リソース取得やロード処理の時間は Core Web Vitals の中でも LCP に大きく影響を及ぼすと考えられます。また LCP に加えて FCP (First Contentful Paint) や TTFB (Time To First Byte) も合わせて測定することでより精度の高い性能改善の施策を講じることができるでしょう。詳細については Largest Contentful Paint (LCP) を見てください。
リソースの先読みに関する API
まずリソースの先読みに関する API を順番に見ていきましょう。ウェブブラウザの立場から見ると、リソースの読み込みはざっくり次のようなステップで構成されています。
[DNS の解決] -> [TCP コネクションの確立] -> [Fetch] -> [Load] -> [Render]
このステップのどこまで先に処理するかによって API を使い分けます。これら API を総称して Pre* APIs と呼んでいます。*にはあらかじめ行う処理の種類が入ります (Prefetch, Preload など)。
これらはメモリやネットワーク帯域を余分に使って先読みをするので、むやみに指定すると重要なリソースの読み込みを妨げて逆効果になります。実環境で測定をしてクリティカルなリソースを洗い出し、それに対してのみ指定するべきです。またこれらはウェブブラウザへの「ヒント」に過ぎないので、状況によっては実行されないこともあります。
dns-prefetch
dns-prefetch は DNS に関するヒントを与える API です。Resource Hints 仕様で定義されています。後ほどアクセスするドメインを link タグで指定することで、その DNS レコードの解決をあらかじめ実行しておくようブラウザに知らせることができます。
<link rel="dns-prefetch" href="https://example.com">
DNS の情報がクライアントや最寄りの DNS サーバにキャッシュされていない場合、その問い合わせは DNS ルートサーバから下位の DNS サーバへと順番に行われるため、その分の待ち時間が発生します。dns-prefetch でこの処理を先に済ませることができます。
dns-prefetch は他の Pre* APIs に比べて軽量な処理ではありますが、その使用は重要なリソース(ドメイン)に対してのみにすべきです。ブラウザは同時に走らせる DNS の問い合わせ処理数に制限をかけています。例えば Chrome ではその並列数を 6 に制限しています。
// Maximum of 6 concurrent resolver threads (excluding retries).
// Some routers (or resolvers) appear to start to provide host-not-found if
// too many simultaneous resolutions are pending. This number needs to be
// further optimized, but 8 is what FF currently does. We found some routers
// that limit this to 6, so we're temporarily holding it at that level.
const size_t kDefaultMaxProcTasks = 6u;
dns-prefetch は HTTP の Link ヘッダーでも指定できます。link タグは HTML のパースの段階で処理が始まりますが、HTTP ヘッダーは(実装依存ですが)それよりも早い段階で処理を開始できます。
Link: <https://example.com>; rel=dns-prefetch
preconnect
preconnect は TCP に関するヒントを与える API です。Resource Hints 仕様で定義されています。後ほどアクセスするドメインを link タグで指定することで、そのドメインへの TCP コネクションをあらかじめ確立するようブラウザに知らせることができます。
<link rel="preconnect" href="https://example.com/">
TCP コネクションの確立には TCP ハンドシェイクや TLS ネゴシエーションで数 RTT かかりますが、preconnect を指定すると確立済みのコネクションを使ってすぐに通信し始めることができます。ただしブラウザはリソースの制約などによって、コネクションシーケンスの途中までしか処理しなかったり、全く処理しないこともあります。あくまでもヒントとして使います。またブラウザが維持するコネクション数は有限で、一定時間使われないコネクションはクローズされるため、クリティカルなドメインに対してのみ使用すべきです。
preconnect には DNS レコードの解決も含まれるため、仕様上は同じドメインに対して dns-prefetch と preconnect を併用する必要はありませんが、ブラウザの対応状況などを考慮して両方を指定することが推奨されています。また link タグの rel は preconnect と dns-prefetch を同時に指定することができますが、互換性の問題から rel 毎に別々の link タグを指定した方が良いようです。例えば Safari では preconnect がキャンセルされてしまうというバグがあります。
<!-- May cause compatibility issue -->
<link rel="preconnect dns-prefetch" href="https://example.com">
<!-- Recommended -->
<link rel="dns-prefetch" href="https://example.com">
<link rel="preconnect" href="https://example.com">
もちろん HTTP の Link ヘッダーでも指定できます。link タグよりも早い段階で処理を開始できる可能性があります。
Link: <https://example.com>; rel=preconnect
preconnect には crossorigin 属性を指定することができます。credentials を持たない cross-origin リクエストのために preconnect する場合に指定する必要があります。
<link rel="preconnect" href="https://example.com/" crossorigin>
crossorigin 属性の挙動については「crossorigin 属性の仕様を読み解く」という記事を書いたのでそちらを見てください。
prefetch
prefetch はリソースのフェッチまでを行う API です。Resource Hints 仕様で定義されています。フェッチしたリソースは HTTP キャッシュに保存されます。プリフェッチされたリソースは次回のナビゲーションで使うことが想定されており、現在のナビゲーションを妨げないよう prefetch によるリソースリクエストは低優先度で処理されます。一方、現在のナビゲーションで使うリソースはそれなりの優先度でさらに積極的に先読みすべきで、後述の preload を使うことが推奨されています。
<link rel="prefetch" href="https://example.com" as="document">
<link rel="prefetch" href="https://example.com/script.js" as="script">
リソースのプリフェッチは XHR や Fetch API でもできますが、それに比べて prefetch が優れている部分は何でしょうか?prefetch なら JavaScript 実行前にプリフェッチを始めることができ、また JavaScript 実行コンテキストへのロード処理を行わないので余計な計算資源を使わずに済みます。さらにリソースの用途を as 属性でブラウザに知らせることができるので、ブラウザが独自の最適化を加える余地が生まれます。
preconnect と同様に prefetch も crossorigin 属性を持ちます。preconnect では crossorigin 属性の意味合いが複雑でしたが、prefetch では単純にリクエストが CORS の場合に crossorigin 属性を指定します。またリクエストの credentials mode に応じて、anonymous または use-credentials といった値を指定します。詳しくは「crossorigin 属性の仕様を読み解く」を見てください。
<link rel="prefetch" href="https://example.com" as="document" crossorigin="use-credentials">
HTTP の Link ヘッダーで指定する場合は次のようになります。
Link: <https://example.com/image.jpg>; rel=prefetch; as=image;
サーバ側で HTTP リクエストのログを取るときに prefetch リクエストと通常のリクエストが見分けられると便利そうです。ブラウザは prefetch リクエストに専用の HTTP ヘッダを付けることでサーバ側で見分けられるようにしています。ただし、このヘッダは仕様で定義されておらず各ブラウザが独自の実装をしている状況です。例えば Chrome では Purpose: prefetch ヘッダを付けています。このヘッダは CORS との相性が悪いので、仕様を決めて Sec-Purpose: prefetch に置き換えるみたいな話もありますが、今のところ置き換わっていないようです。詳しくは Chrome の feature dashboard や仕様の議論を見てください。なお手元で試したところ Firefox 84 は X-Moz: prefetch を使っているようです。使う場合はご自身で調べてください。
preload
preload はリソースのロードまでを行う API です。preload は Resource Hints 仕様ではなく Preload 仕様で定義されています。prefetch と同様に as 属性でリソースの用途を指定することで、それに応じたロード処理を行います。仕様によるとロードされたリソースは preload cache に保存することになっていますが、この preload cache はまだ明確に定義されておらず、実装依存となっています。Chrome ではレンダラプロセスが持つ map オブジェクトによって管理されています。
<link rel="preload" href="https://example.com" as="document">
<link rel="preload" href="https://example.com/script.js" as="script">
preload されたリソースはすぐに使える状態になるため、現在のナビゲーションで確実に使われるリソースに対してのみ指定すべきです。Chrome では window.onload が呼ばれてから 3 秒以内にそのリソースが使われなかった場合はデベロッパーコンソールに警告を表示します。
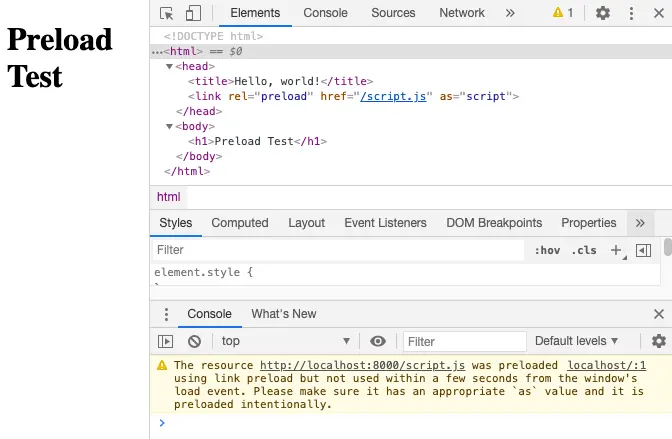
preload の実装状況はまちまちです。例えば Chrome では実装上の理由から as=”worker” をサポートしていません (無視されます)。
残念ながら Chromium-based ブラウザでは preload の as=script for importScripts も as=worker も実装されてないです。実装難易度がかなり高いので直近で対応する予定も今のところないです・・・
— nhiroki (@nhiroki_) November 24, 2020
[1]https://t.co/vD8MwOYrBC
[2]https://t.co/1tgpM5OgIE
HTTP の Link ヘッダーで指定する場合は次のようになります。
Link: <https://example.com/lmage.jpg>; rel=preload; as=image;
modulepreload
preload に似た機能に modulepreload があります。これは module script に特化した preload で、HTML 仕様で定義されています。module script 専用なので as 属性を持ちません。
<link rel="modulepreload" href="module.mjs">
preload では指定したリソースのみをプリロードするのに対し、modulepreload は指定した module script がプリロードされるのに加えて、そこから static import2 している module script も全てプリロードしてモジュールグラフを構築するところまで処理します。また preload がリソースを preload cache に保存するのに対し、modulepreload では module map と呼ばれるキャッシュに保存します。
例えば下図のようなグラフ構造を持つモジュールスクリプト top-level1.mjs をプリロードするとします。
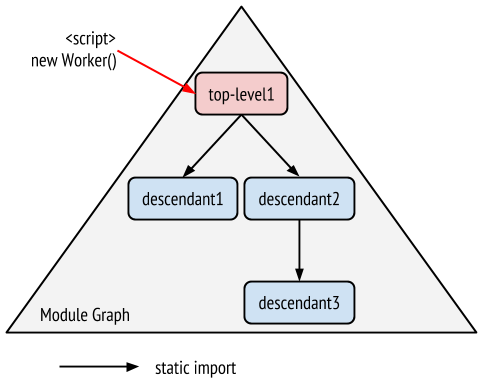
modulepreload で top-level1.mjs を指定すると、そこから static import されている descendant1.mjs, descendant2.mjs, descendant3.mjs も同様にプリロードされます。
<!-- This preloads top-level1.mjs and descendant{1,2,3}.mjs -->
<link rel="modulepreload" href="top-level1.mjs">
一方 dynamic import2 はスクリプトを実行しないと処理できないため、プリロードされません。dynamic import を先読みしたい場合は別途 modulepreload で指定する必要があります。例えば下図のように descendant2.mjs が top-level2.mjs を dynamic import しているとします。
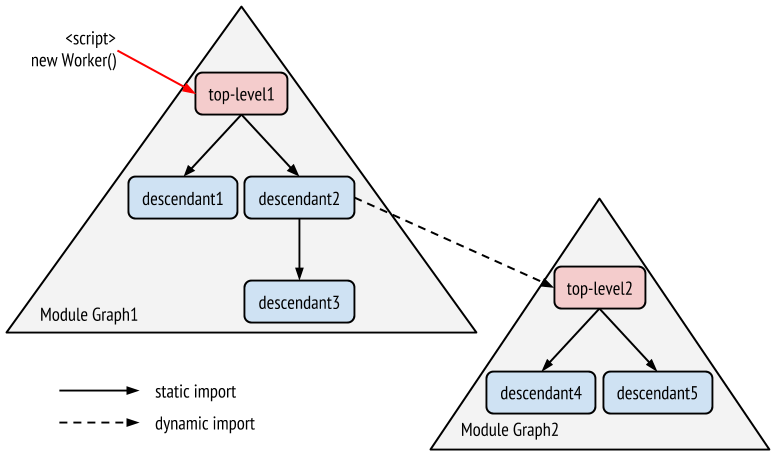
top-level2.mjs も先読みするには別の link タグで指定します。
<!-- This preloads top-level1.mjs and descendant{1,2,3}.mjs -->
<link rel="modulepreload" href="top-level1.mjs">
<!-- This preloads top-level2.mjs and descendant{4,5}.mjs -->
<link rel="modulepreload" href="top-level2.mjs">
モジュールグラフの深部で static import されているスクリプトは、それを発見するまでに数 RTT かかります。一つ目の図の例だと、descendant3.mjs をロードするには top-level1.mjs と descendant2.mjs をロードして descendant3.mjs に対する import 文を見つける必要があります。これを並列に処理するために modulepreload を列挙するという手法があります。
<link rel="modulepreload" href="top-level1.mjs">
<link rel="modulepreload" href="descendant1.mjs">
<link rel="modulepreload" href="descendant2.mjs">
<link rel="modulepreload" href="descendant3.mjs">
これは一種のマニフェストのように働きます。一見すると descendant3.mjs を直接プリロードする場合と descendant2.mjs からグラフを辿って preload する場合の二回 descendant3.mjs がロードされるように見えますが、一度ロードされた module script は module map に入れられて共有されるため、同じ module script が二回以上ロードされることはありません。列挙することでロードタイミングを早めることができますが、グラフ構造が変わるたびに列挙しなおさなくてはいけないため、メンテナンスしにくいのが難点です。
prerender
prerender はページのレンダリングまでを行う API です。Pre* 系 API の中では最もアグレッシブな先読みになります。レンダリングをするといってもユーザが実際にそのページにナビゲーションするまではユーザには見えません。
<link rel="prerender" href="https://example.com">
Chrome における prerender はその名に反してリソースのプリフェッチをするだけでプリレンダリングはしていません。メモリ消費量や機能上の懸念によりそのような実装になっています。ただし、プリフェッチといっても <link rel=prefetch> より高度な先読みをしており、JavaScript の実行や描画は行わずとも、そのページ内で使用されるサブリソースをスキャニングし、それらもプリフェッチします。このプリフェッチを NoState Prefetch と呼んでいます。詳しくは こちらの記事を参照してください。この挙動は HTTP 仕様で定義されたものではない(仕様違反ではないです。仕様では prerender で何をすべきか定義しておらず、実装依存となっています)ため、prerender がプリフェッチであることを仮定してアプリケーションを書くべきではありません。例えば JavaScript が実行されないことを仮定してはいけません。他のブラウザで予想外の挙動をする可能性があります。ちなみに NoState Prefetch も Purpose: prefetch ヘッダを付けてリクエストが行われます。
現在 Chrome (Chromium) では新たな Prerender API の仕様提案 (Speculation Rules)とその試験実装を行っています。新しい API では実際にプリレンダリングまで行い、ナビゲーションしたときに即座に表示されるようになる見込みです。これについてはまた改めて記事を書きたいと思います。
Chromium で新しい Prerender API を試験実装しています。実は現在の link rel=prerender 実装では NoStatePrefetch と呼ばれる少しリッチな先読みをしているだけでページの事前描画はしていないんですが、諸々の課題をクリアして prerender を再実装し instant な page load を目指しています #nhspec https://t.co/seSAGgeOHI
— nhiroki (@nhiroki_) December 16, 2020
リソースの優先度制御に関する API
ここまで Pre* APIs を紹介しました。Pre* APIs は今後必要となるリソースを明示的に列挙し、それを先読みする機能群でした。ここからはリソースの先読みではなく、読み込みの優先度を制御する API を紹介していきます。
Priority Hints
Priority Hints はアプリケーションからリソースの優先度を指定する API です。優先度はレンダリングエンジン内のスケジューリングに使われたり、 HTTP/2 リクエストの優先度に反映されたりします。
優先度の指定は img や script タグに importance 属性を指定することで行います。属性値は high, low, auto の三種類です。
<img src="img/unimportant.jpg" importance="low">
<script src="important.js" importance="high"></script>
この API は Chrome 70 にて実装され、機能をローンチする前の性能評価実験が行われました。残念ながらあまり芳しい結果が得られておらず、現在のところ機能がローンチする目処は立っていません。
Lazy Loading
Pre* APIs は将来必要になるリソースをあらかじめ取りに行く機能だったのに対し、Lazy Loading はすぐに必要ではないリソースの読み込みを遅らせることで、今すぐ必要なリソースの読み込みを相対的に優先付ける機能です。HTML 仕様で定義されています。すぐに必要ではないリソースとは、例えば viewport 外の画像などが該当します。
Lazy Loading は img や iframe タグに loading 属性を指定することで使えます。属性値は lazy と eager の二種類で、lazy はリソースの読み込み条件が揃うまで遅延し、eager はリソースの読み込みを直ちに行います。デフォルト値は eager です。
<img src="foo.jpg" loading="eager">
<img src="bar.jpg" loading="lazy">
Lazy Loading については Jxck さんの「画像最適化戦略 Lazy Loading 編」という記事に詳しくまとまっています。
スクリプトの async と defer
script タグに async や defer を指定することでスクリプトのフェッチと実行のタイミングを指定することができます。
<script src="sync.js"></script>
<script src="async.js" async></script>
<script src="defer.js" defer></script>
デフォルトの挙動では、script タグは同期的にスクリプトのフェッチと実行を行います。defer が指定されると、スクリプトのフェッチが HTML パーシングと並行して行われ、フェッチが終わって更にパーシングが終わった時点でスクリプトを実行します。同様に async もスクリプトフェッチを HTML パーシングと並行して行いますが、こちらはパーシングの完了を待たずにフェッチが終わった時点でスクリプトを実行します。
さらにスクリプトの種類が classic か module かによって挙動が変わります。Classic script の場合はデフォルトの挙動が同期的なフェッチと実行で、オプションで defer もしくは async を指定できます。一方 module script はデフォルトの挙動が defer で、オプションで async を指定できます。
次の図は HTML 仕様からの引用です。オプションやスクリプトの種類毎の挙動が分かりやすくまとまっています。
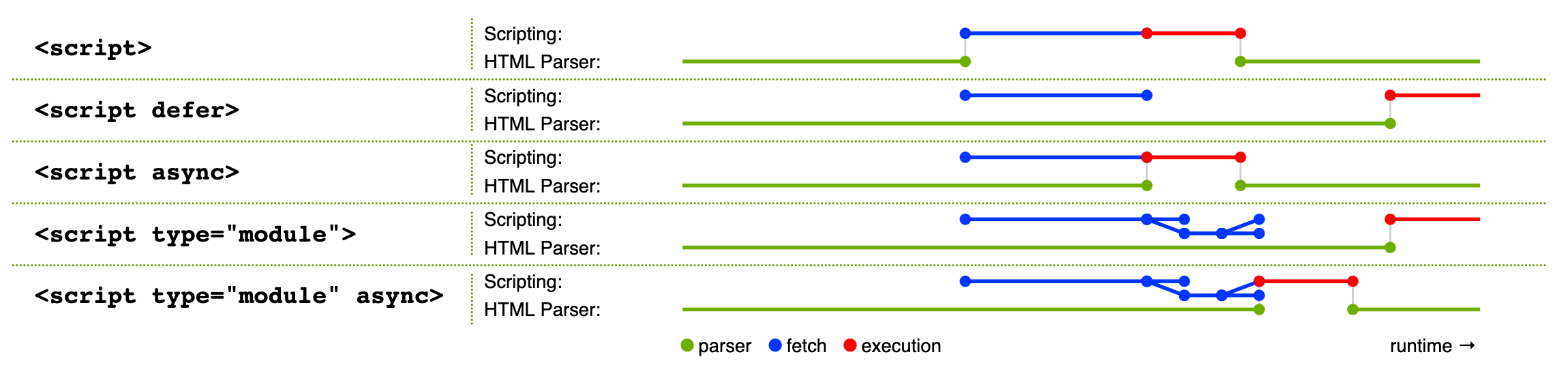
なお、async や defer を指定するとロード処理の優先度が下がる可能性があるので注意が必要です。詳しくは「JavaScript Loading Priorities in Chrome」を見てください。
その他の API
本節では柔軟なリソース読み込みを助ける API を紹介していきます。
HTTP/2 Server Push
Pre* APIs はブラウザから先読みリクエストを行うための API でした。ブラウザが先読みすべきサブリソースについて知るのは、一番早くてもメインリソースのレスポンスヘッダが届いたタイミングです。一方、サーバ (アプリケーション) はブラウザが後でリクエストしてくるサブリソースのことを事前に知っているはずです。そこで、ブラウザがサブリソースリクエストを送ってくる前に、先んじてサブリソースレスポンスを送りつけてしまう (プッシュしてしまう) のが HTTP/2 Server Push です。ブラウザへプッシュされたレスポンスはコネクションに紐付いた Push Cache に保存され、ブラウザがリクエストしてきたタイミングで消費されます。その名前の通り、本機能は HTTP/2 の目玉機能として仕様定義されました。もちろん HTTP/3 の仕様にも含まれています。
一見すると Server Push はサブリソースフェッチのラウンドトリップ数を減らす銀の弾丸のように思えますが、問題もあります。その一つはサーバがブラウザのキャッシュ状況を考慮せずに一方的にレスポンスを送りつけることです。もしブラウザがキャッシュ済みのリソースを保持している場合、プッシュされたレスポンスやそれを送るために使用されたネットワークが無駄になります。これを解決するためにブラウザの持つキャッシュ情報をダイジェストにして送る Cache Digest という仕組みが提案されていますが、キャッシュ情報を生成するコストや実装の複雑さなどからどのブラウザにも実装されていません。詳しくは Jxck さんの「Cache Digest と HTTP2 Server Push の現状」を読んでください。
その他、Server Push を使う上で注意すべき点は「HTTP/2 push is tougher than I thought」という記事に詳しくまとまっています。
Chromium では既に HTTP/2 Server Push が実装されていますが、使用方法が難しく性能を最大限発揮できるユースケースに乏しいこと、処理の複雑さに起因するメンテナンスコストの増加などを理由に廃止することが提案されています。また HTTP/3 でも Server Push を実装しないと明言しています。その代替としては次に紹介する 103 Early Hints が挙げられています。
103 Early Hints
HTTP は最終的なレスポンス (例えば 200 OK) を返す前に補足情報を載せたレスポンスを返すことができます。このレスポンスには HTTP ステータスコード 1xx が使われ、それらは informational レスポンスと呼ばれます。Informational レスポンスについては「Resource Timing と HTTP ステータスコード 1xx」という記事を見てください。
Informational レスポンスと最終レスポンス (non-informational レスポンス) は次のような順番でサーブされます。
1xx --> 1xx --> ... --> 1xx --> 200
103 Early Hints はこの informational レスポンスの一つで、ページ表示に必要になるリソースのヒントをサーバからクライアントへ与えるのに使います3。特にメインリソースリクエストに対してサーブすることが想定されています。103 Early Hints はあくまで HTTP ステータスコードであり、それ自体にはリソースを先読みする機能はありません。103 Early Hints の Link ヘッダに Pre* API を指定することで先読みを行います。
HTTP/1.1 103 Early Hints
Link: </style.css>; rel=preload; as=style
Link: </script.js>; rel=preload; as=script
一般的にサーバはメインリソースリクエストを受信するとデータベースなどへアクセスしてレスポンスを構築し、それをクライアントへ返送します。クライアントがサブリソースの読み込みを開始するのはその後になるため、このレスポンス構築処理が遅れるとそれだけページ全体の表示が遅れてしまいます。これを避けるため、サーバはまず 103 Early Hints を送出し、それからメインリソースレスポンスの準備をします。これにより、サーバがメインレスポンスを構築している間に、ブラウザはサブリソースの先読みをオーバラップさせることができます。
似たような仕組みに前述の Server Push があります。Server Push は必要なリソースをサーバから直接プッシュするのに対し、103 Early Hints ではサーバはヒントを与えるだけで実際にリソースをフェッチするかはクライアントに任せます。本当に必要なリソースであればサーバからさっさとプッシュした方がブラウザから改めてリクエストを送り直してもらわずに済む分早く処理ができそうですが、クライアントのキャッシュ状況などを考慮しないと性能が出ないことが知られています。103 Early Hints ではクライアントが自身のキャッシュ状況に応じてリクエストできるため、この問題を回避することができます。
また、同様の仕組みを HTTP の Transfer-Encoding: chunked を使って実現できます。サーバはメインリソースレスポンスを完全に構築する前に、サブリソースの先読みに必要な部分だけ chunked レスポンスとしてクライアントに返送します。クライアントは受け取った部分をパースし、サブリソースの読み込みを開始します。その裏でサーバはメインリソースレスポンスの構築を継続します。この手法は Early Flush として知られています。詳しくは「Flushing the Document Early」を見てください。リソースの chunking をアプリケーション側でやる必要があり、103 Early Hints に比べると処理が複雑になるというデメリットがあります。
2021 年 5 月現在、Chromium にてメインリソースリクエストに対する 103 Early Hints の実装が進められており、また Fastly と共同で予備的な性能評価実験を行っています。
Service Worker と Cache Storage
Service Worker はバックグラウンドで動くイベント処理基盤です。その機能の一つにページからのリクエストに対してイベントを発火し、その処理を JavaScript で制御できるブラウザ内 HTTP プロキシのような機能があります。Cache Storage はリクエストとレスポンスをキーバリューとしたストレージ API です。
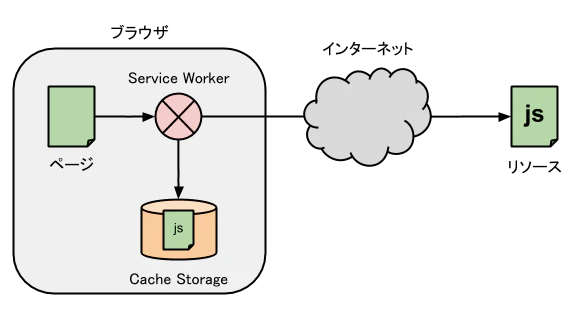
Service Worker と Cache Storage を組み合わせることで、リソースの読み込みを柔軟に制御することができます。例えば、あらかじめ Cache Storage に必要となるリソースを保存しておき、Service Worker がリクエストをインターセプトしたときにその保存済みのリソースを返すという使い方ができます。同様のことはブラウザキャッシュでもできますが、一般的にブラウザキャッシュの挙動を細かく制御するのは難しいのに対し、Service Worker なら JavaScript で柔軟に制御できます。他にも Cache Storage からの読み込みとネットワークからの読み込みを競争させて早く処理できた方を採用したり、キャッシュされたリソースを返しつつも裏ではリソースの更新をかけておくといった使い方ができます。Service Worker によるキャッシュ戦略については「The offline cookbook」という記事が詳しいです。なお、Service Worker 自体はリソースをフェッチする仕組みを持たないため、Fetch API などで取ってくるか、Cache Storage に組み込みの機能で取ってくる必要があります。
また、Service Worker はネットワークがオフラインのときでも起動することができ、キャッシュ済みのリソースを返すことでオフライン対応したアプリケーションを作ることができます4。これはブラウザキャッシュでは実現できない機能です。
Web Bundle
Web Bundle はページ描画に必要なリソースを一つのファイルにバンドルし、それを丸ごとウェブブラウザへロードする仕組みです。バンドルにすることでリソース毎にリクエストを投げる必要がなくなるため、その分ネットワーク処理にかかる時間を減らすことができます。
webpack のような外部ツールによるバンドルファイルと何が違うのでしょうか?外部ツールによるバンドルファイルはウェブブラウザからすると一つのリソースにしか見えないため、それがそのままブラウザキャッシュへと保存されます。
// URL A でホストされたバンドルファイルとしてキャッシュ
Non-WebBundle (URL A) contains...
- Resource A1 (URL A1)
- Resource A2 (URL A2)
- Resource A3 (URL A3)
一方、Web Bundle によるバンドルファイルはウェブブラウザがその内部構造を知ることができるため、バンドルを構成するリソース毎にブラウザキャッシュへ保存し、ロードすることができます。これによりキャッシュの再利用率を高め、リソースの読み込みを柔軟に行えるようになります。
// URL B1, B2, B3 にホストされた個別のリソースとしてキャッシュ
WebBundle (URL B) contains...
- Resource B1 (URL B1)
- Resource B2 (URL B2)
- Resource B3 (URL B3)
Web Bundle には単純なバンドル以上の様々なユースケースがあります。詳しくは Jxck さんの「WebBundle によるコンテンツの結合と WebPackaging」という記事が詳しいのでそちらを見てください。
まとめ
本記事ではウェブブラウザが提供するリソース読み込みに関する API を網羅的に紹介しました。各 API の使い方や利用例を紹介した記事はいくつもありますが、それらを包括的に紹介する記事があまりないなと感じたのが本記事を書き始めたきっかけでした。
これらの API には必ずトレードオフが存在します。先読みをすればその分リソースを消費します。特定のリソースの優先度を上げればそれ以外のリソースの優先度は相対的に下がります。効きそうな API をやみくもに使うのではなく、各種メトリクスやデバッガツールを駆使してボトルネックを洗い出し、それに最も効果的な API を吟味して使うようにしましょう。
ちなみに今回紹介した API の Chromium 実装の多くは私も所属している東京の Chrome ブラウザ開発チーム (Loading チーム) で面倒を見ています。適用してみて性能改善できた事例などがあれば、是非ブログなどで共有していただければと思います。実装バグを見つけた場合はバグトラッカーへお知らせください :)
参考文献
- Web Almanac 2020 - Chapter 21 Resource Hints (2020/12)
- ChromeのHTTP/2サーバプッシュサポート廃止検討と、103 Early Hintsについて (2020/11)
- Intent to Remove: HTTP/2 and gQUIC server push (2020/11)
- Web Speed Hackathon Online 出題のねらいと解説 (2020/07)
- WebBundle によるコンテンツの結合と WebPackaging (2019/11)
- Establish network connections early to improve perceived page speed - web.dev (2019/07)
- 画像最適化戦略 Lazy Loading 編 (2019/05)
- JavaScript Loading Priorities in Chrome (2019/02)
- Cache Digest と HTTP2 Server Push の現状 (2019/01)
- Introducing NoState Prefetch (2018/07)
- HTTP/2 push is tougher than I thought (2017/05)
- Preload, Prefetch And Priorities in Chrome (2017/03)
- Preloading modules (2017/12)
- HTTP の新しいステータスコード 103 Early Hints
- The offline cookbook (2014/12)
- Flushing the Document Early (2009/05)
注釈
-
Web Worker や Service Worker の場合は、最初に読み込まれる JavaScript ファイル (Top-level Worker Script と呼びます) がメインリソースになります。 ↩
-
スクリプトの import には static import と dynamic import があります。詳しくは「JavaScript のスクリプトインポートを正しく使い分けようという話」を見てください。 ↩ ↩2
-
より正確には、103 Early Hints レスポンスは最終レスポンスが持つヘッダを事前に送るのに使います。最終レスポンス生成中にヘッダ情報が変わった場合は、103 Early Hints を複数回送ることも許可されています。詳しくは RFC 8297 を参照してください。 ↩
-
Cache Storage API は Service Worker 仕様の一部として策定されています。これはオフライン機能の実現のために、リクエストとレスポンスをキーバリューストアのように手軽に保存できて、かつ Opaque レスポンスも格納できるストレージが必要だったからです。Opaque レスポンスはボディの中身が読めないため、IndexedDB などに保存することができません。 ↩