論文|MESH: Compacting Memory Management for C/C++ Applications (PLDI 2019)
「MESH: Compacting Memory Management for C/C++ Applications」という論文を読んだのでその紹介です。arXiv.org で公開されています。PLDI 2019 で採択されている論文のドラフトだそうです。私は v2 を読みました。ソースコードが GitHub (plasma-umass/Mesh) で公開されています。
免責 読み間違えている可能性があります。正確な情報が欲しい方は必ず論文を読んでください。誤りの指摘や補足、議論などは GitHub Issue や Twitter へお願いします。
読んだ動機
- C/C++ でリロケーションせずにコンパクションを行う手法に興味があった。
- Speedmetor 2.0 benchmark を走らせた Firefox でメモリ消費量が減ったと報告されており、ブラウザ開発者として気になった。
- Chromium (Chrome) の開発者メーリングリストにスレッドが立ち始めた。
概要
本論文では MESH と呼ばれる C/C++ メモリアロケータライブラリの設計と実装が論じられている。
特徴
MESH の主な特徴は以下の通り。
- 標準ライブラリの
malloc()を置き換えて使うメモリアロケータライブラリ。 - Linux と Mac OSX に対応。マルチスレッド環境でも使用可能。
- コンパイル時にリンク、もしくは
LD_PRELOADやDYLD_INSERT_LIBRARIESで動的に読み込んで使用。 - Segregated-fit 型アロケータ。あらかじめ決められたブロックサイズ (サイズクラス) 毎にフリーリストを構成し、要求サイズが収まるブロックのリストからメモリを割り当てる1。
そして最大の特徴は「リロケーションせずにコンパクションが行える」ことである。コンパクションはメモリフラグメンテーションを解決し、メモリの使用効率を上げるために行われる。一般的にコンパクションはオブジェクトのメモリ配置の変更 (リロケーション) を伴うため、オブジェクトの持つポインタも書き換える必要がある。これは C/C++ のようにポインタがアプリケーションに露出している言語 (unmanaged language) では困難で、それを実現するには生ポインタを使わずに専用のスマートポインタで頑張るなど C/C++ アプリケーション側の書き換えが必要になる。一方、MESH ではリロケーションを行わないためポインタが変わらず、既存のアプリケーションを書き換えずに使用できる。
(2019/02/26 追記) これは後述の「MESH の新規性」の項で説明するが、この「リロケーションせずにコンパクションを行う」手法自体は MESH が初出ではない。MESH はメモリ割り当てのアルゴリズムにランダム性を加えることで、コンパクションを行える可能性を高め、最悪ケースを避けているところに新規性がある。
メモリ管理とコンパクション
MESH では span と呼ばれる固定長のブロック (連続した 4K pages) でメモリを管理する。実際のメモリ割り当ては span 内の page を更に細かく区切った固定長の単位 (object) で行う。Object の大きさはサイズクラスによる。各 object には span-local な offset 番号が与えられており、それを使って割り当て済みかどうか管理する。
ある 2 つの page 内の割り当て済み object の offset が被らなければ両者はマージ可能である。マージ可能であることを meshable と呼び、マージ操作を mesh と呼ぶ。例として、2 つの page (page-a と page-b) について考える (下図参照)。
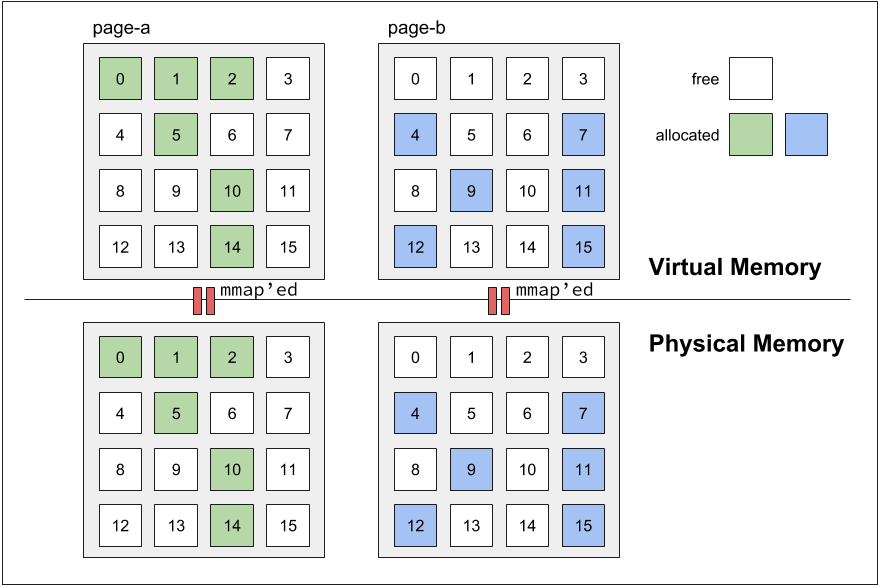
図: マージ可能 (meshable) な状態の page ペアの例。この例では各 page は 16 個の object を持ち、それぞれに offset 番号が与えられている (object 数はサイズクラスによって変わる)。Page 毎に対応する物理メモリを持っている。page-a と page-b の割り当て済み object の offset はオーバラップしていない。論文内の Figure 1 (a) を基に作成。
通常コンパクションは連続した領域を新たに (もしくは既存の領域を再利用して) 確保し、そこにオブジェクトのコピーを行い、元の領域は解放する。これだと仮想アドレスが変わってしまうため。ポインタの書き換えが必要になる。一方、MESH では page-b から page-a へとオブジェクトをコピーしたら、page-b を解放するのではなく、それの仮想アドレスが指す物理メモリを page-a のものへと書き換えてしまう。これはページテーブルの書き換えによって実現される。これにより仮想アドレス (ポインタ) は変わらないが、参照先はコンパクションされた領域へとすり替わる。
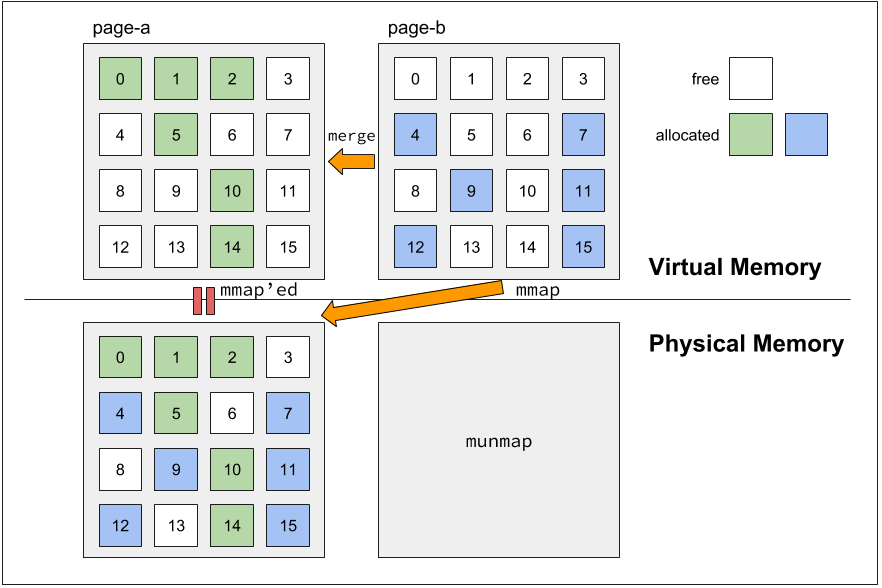
図: マージ後の page ペアの例。page-b の仮想メモリは解放せず、物理メモリへのマッピングだけを切り替える。page-b に対応していた物理メモリは OS に返す (munmap() する)。論文内の Figure 1 (b) を基に作成。
ここでは page 単位の mesh について見てきた。実際の mesh は span 単位で行われる。
ページテーブルの書き換え
MESH が管理するメモリ領域は memfd_create() で作られたインメモリの一時ファイルを mmap() して確保する。mmap() はファイル内の同一 offset を複数の仮想アドレスにマップすることができるので、これによりページテーブルのアップデートを行う。
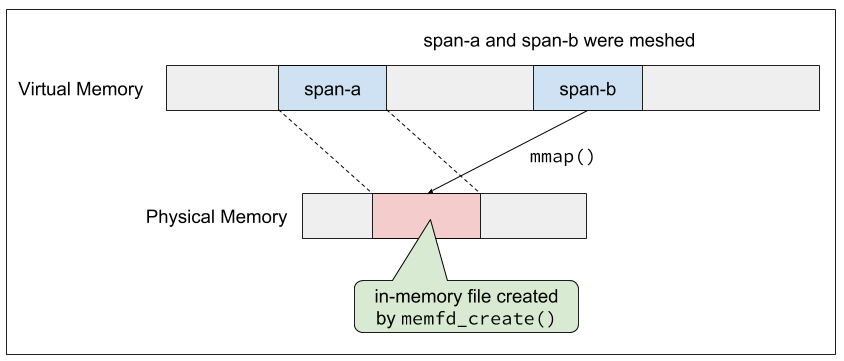
図: mmap() によるページテーブルの書き換え。
MESH はマルチスレッド対応のメモリアロケータであり、コンパクション中に別のスレッドが対象のオブジェクトを読み書きしようとする可能性がある。これに対し、MESH は二つの不変条件を仮定する。
- Mesh 中のオブジェクトは他のスレッドから正しく read できる。
- Mesh 中のオブジェクトに対して他のスレッドから write されることはない。
(1) については mmap() のアトミック性によって保証される。(2) については MESH 独自の write barrier 機構を使う。この機構は、まず mesh 元の領域 (span-b) を mprotect() で読み込み専用にする。もし mesh 中に書き込みが要求された場合は sigfault ハンドラでトラップし、mesh 処理が終わるまで待ってから再度処理を行う。仮想アドレスが書き換わらないため、再処理はそのまま行える。
MESH の新規性
実はここまで述べた mesh 処理は MESH が初出ではない。元々は Hound という C/C++ 向けメモリリーク検知器が提案したものらしく、それについては関連研究の項に書かれている。Hound は meshable な page をリニアスキャンにより求めており、また page の割り当ても meshable である可能性を高める工夫はされていないそうで、一般的なメモリアロケータとして実用できるものではないとのこと。
それに対し MESH では、meshable な span ペアを作りやすくする工夫と、それを見つけやすくする工夫を行うことで速度と効率性を高めて実用的にしている。
Meshable な span ペアの作り方
前項の通り、MESH の新規性は mesh 処理自体ではなく、meshable な span ペアの作り方とその見つけ方にあるらしい。先に言ってしまうと、両者にランダム性を持たせることでこれを実現している。
まず meshable な span ペアを作りやすくする工夫を見ていく。MESH では ShuffleVector と呼ばれるデータ構造を使ってこれを行う。ShuffleVector は span 内の未使用 object の offset 番号をランダムな順番で格納した固定長配列である。Span 毎に存在する。ランダムな順列の生成には Knuth-Fischer-Yates shuffle アルゴリズムが使われる。
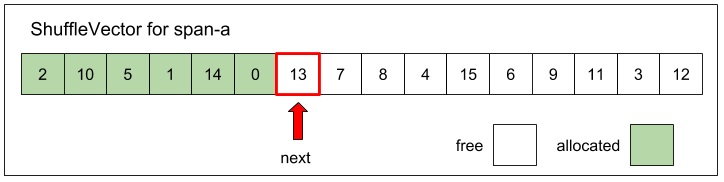
図: span-a (page-a) の ShuffleVector の例。この span に対する次のメモリ割り当て要求は offset 番号 13 の位置にある object によって行われる。
オブジェクト割り当て時に配列の先頭から順番に offset 番号を取り出し、それに対応する object を割り当てる。これにより object の割り当てをランダムな offset 順で行える。ShuffleVector は未使用の object の先頭位置 (インデックス) を覚えておき、オブジェクト解放時にはそのインデックスを一つ前にずらして、解放された object の offset 番号を再度格納する。さらに配列内の別の未使用 offset 番号と適当にスワップすることでランダム性を維持する。各 span が割り当てる object の順番がランダムになることで、span 間の重なりが生じにくくなる。
Meshable な span ペアの見つけ方
Meshable な span ペアの発見には SplitMesher と呼ばれる独自のアルゴリズムを用いている。このアルゴリズムでは、ランダムな順番に並んだ span のリストを半分に分け、ループを回してそれぞれのリスト間でペアができるか順番に見ていく。このとき各 span が検査される回数を t に制限することで、実行時間とメモリ効率のトレードオフを実用的な範囲に収めることができる。筆者らによると t には 64 を指定するとバランスが取れるらしい。

図: SplitMesher アルゴリズムの擬似コード。論文より引用。
正直な所、このアルゴリズムについてはよく分かっていない。”the randomly ordered span list S” とあるが、これのランダム性はどのように決まるんだろう?それ以外にはランダム要素はないように見える。
SplitMesher で見つけたペアはリストに保存しておき、あとでまとめて mesh 処理を行う。
実装
実装に関しては元論文やソースコードを読んでもらう方が良いと思うので、ここでは概要だけ述べる。
サイズクラス
前述の通り、MESH はあらかじめ決められた大きさ (サイズクラス) のブロックのフリーリストを持つ segregated-fit 型のアロケータである。使用するサイズクラスは以下の通りとなっている。
- ~ 1024 bytes : jemalloc と同じサイズクラスを採用。
- 1024 bytes ~ 16 Kbytes : 2 のべき乗ごとのサイズクラス。
- 16 Kbytes ~ : Global Arena から個別に直接割り当て。
4 Kbytes 以上のオブジェクトは page サイズを超える大きさとなるため mesh 処理の対象外。解放時に直接 OS に返却する。
コンポーネント
重要なのは次の 4 つ。
- MiniHeaps: span のメタデータや割り当て状況を管理。MiniHeaps は後述する Thread local heaps もしくは Global heap のどちらかに管理される。
- Attached MiniHeaps : Thread local heaps によって管理。特定のスレッドに束縛されていることから attached と呼ぶ。小さいオブジェクト (16 Kbytes 以下) はここから割り当てられる。
- Detached MiniHeaps : Global heap によって管理。特定のスレッドに束縛されていないことから detached と呼ぶ。Thread-local heaps のもつ attached MiniHeaps の空きが少なくなってきたら、それと交換する。
- Shuffle vectors: MiniHeap が span から効率的にランダムアロケーションを行えるようにするために使われる。Thread local heaps もしくは Global heap によって管理される。サイズクラス毎に存在する。
- Thread local heaps: 各スレッドがそれぞれ持つヒープ。各スレッドからのオブジェクト割り当て要求はまずここに行われる。スレッドローカルなのでロックやアトミック処理抜きでメモリ管理ができる。大きなオブジェクト (16 Kbytes より大きい) の割り当て要求は次の Global heap に移譲される。
- Global heap: 全スレッドで共有。状態の管理や MiniHeaps の thread local heaps への割り当て、大きなサイズのオブジェクトの割り当て、thread local heaps をまたぐオブジェクトの解放、mesh 処理のコーディネートなどを行う。
Mesh 処理の形式的評価
論文第 5 章では mesh 処理を形式的に評価している。具体的には、span を「要素に 0/1 を持つ長さ b の binary string」、mesh を「n 個の binary string を持つ set から meshable な string ペアを見つけてマージして片方を解放する処理」として形式化し、次のような問題に帰着させている。
【問題】長さ b の binary string を n 個持つ set が与えられた時、binary string の解放数を最大にする mesh 方法を見つけよ。
詳細は分かりませんが、これはグラフ理論の最小クリーク被覆問題 (Minimum Clique Cover) に変換できて、それを求めるのは NP-hard らしい。そこで、問題に制限やランダム性を加えることでより高速で実用的なアルゴリズムにしたものが SplitMesher アルゴリズムとのこと。なお実装上はグラフを構築する必要はない。私はこの辺りの証明は全然分かってないので有識者の解説を求む。
ベンチマーク評価
メモリ使用量とオーバヘッドに関する評価
- Firefox で Speedmetor 2.0 benchmark を走らせた。1% 以下の Speedmetor スコアの低下が見られたが、16% のメモリ消費量を削減できた。
- Redis の公式テストスイートを使って測定。39% のメモリ消費量を削減できた。
- SPECint 2006 benchmark suite を使って測定。わずかながら実行時間のオーバヘッドはあるものの、全体的に若干量のメモリ使用量を削減できた。メモリ割り当ての多いアプリケーションではピーク時のメモリ使用量を大きく減らすことができた。
割り当てのランダム化に関する評価
(1) meshing 無効、(2) meshing は有効だが randomization が無効、(3) meshing も randamization も有効、の 3 パターンで測定:
- Firefox と Redis では randomization の有無による違いは見られなかった。これらのアプリケーションがイレギュラー (ランダム) なメモリ割り当て特性を持っているからだと筆者らは考えている。
- より一般的なメモリ割り当てのパターンを試すため、Ruby でベンチマークを書いて評価。jemalloc を使った場合と比べて、randomization を有効にするとオーバヘッドは増えたが、メモリ消費量は減った。
実験環境やより具体的な数値は論文参照。
関連研究
省略。気が向いたら書く。
雑感
面白い論文でした。特に memfd_create() と mmap() を駆使してリロケーションを避けるのはなるほどと思った。ざっくりとした仕組みが分かって良かった。
気になったことなど・・・
- SplitMesher アルゴリズムがよく分からなかった。Span のペアリングを適当なところで打ち切ってるだけに見えるんだけど、どのあたりにランダム性が効いてるんだろう?
- 論文内でたびたび出てくる “the classical Robson bounds” というのが分からなかった。メモリ割り当てのフラグメンテーションに関する制約っぽい?1977 年に書かれた論文で紹介されているようなので、そのうち読みたい。
あと MESH に関する議論がいくつか起こっていて興味深いので引き続き追っていきたい。
- Chromium のメーリングリストでは、MESH の手法が Chromium のメモリアロケータで使えないか議論されている。
- Hacker News のスレッド。
注釈
-
固定長にすることで、内部フラグメンテーションを防いだり、割り当て可能なブロックの探索にかかる時間を抑えたりできる。あと、並列化しやすくなったりする。 ↩